이번 장의 주제는 I/O 중심의 작업을 비동기로 수행하는 방법이다.
- 하드웨어 장치가 직접 태스크를 처리할 수 있기때문에 스레드와 CPU를 사용할 필요가 없어진다.
- 그럼에도 스레드 풀은 여전히 중요한 역할을 담당한다. -> I/O 작업의 결과 처리하는데 스레드풀 내의 스레드가 사용되기 때문
윈도우 운영체제가 I/O 작업을 수행하는 방법 ( 동기 / 비동기 )
하드웨어 장치 : 고유의 회로기판을 가지며, 이 장치를 어떻게 제어해야 하는지를 정확히 알고 있는 작지만 특수한 목적의 컴퓨터를 가짐
- 하드 디스크 드라이브의 회로 기판에는 드라이브를 어떻게 회전시키고 헤드를 원하는 트랙으로 어떻게 이동시키는지
- 디스크로부터 어떻게 데이터를 읽거나 기록하는지, 읽거나 쓸 데이터를 컴퓨터의 메모리와 어떻게 주고 받는지에 대해 구현
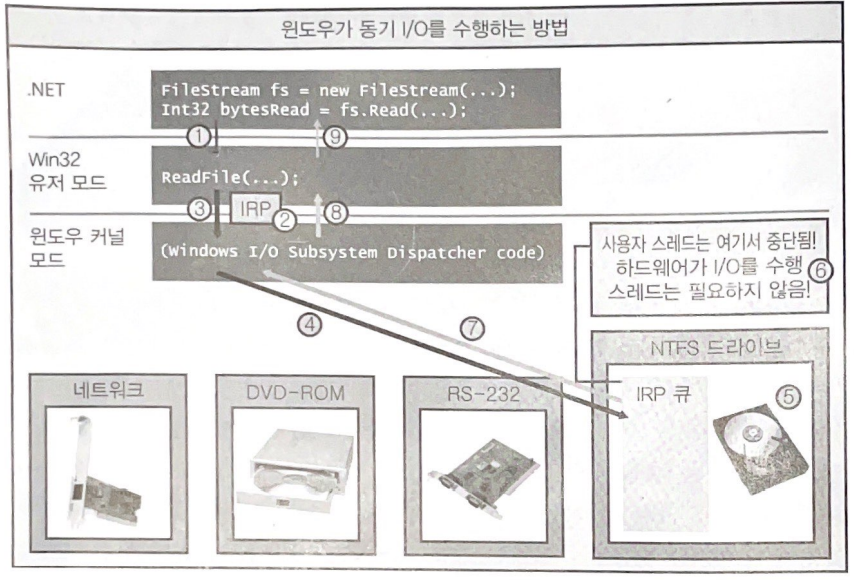
- FileStream의 Read 메서드를 호출하면 스레드는 관리 코드에서 네이티브/유저 모드 코드로 전환되고, Read 메서드의 호출은 내부적으로 Win32의 ReadFile 함수를 호출한다.
- 이제 ReadFile은 IRP라고 부르는 조그만 데이터 구조체를 할당한다.
- ReadFile은 이제 네이티브/유저모드 코드에서 네이티브/커널모드로 전환 작업을 수행하여 윈도우 커널로 이동한다. 이때 IRP 데이터 구조체도 커널로 전달된다.
- 윈도우 커널은 IRP 내의 디바이스 핸들을 이용하여 어느 디바이스로 요청이 전달되어야 하는지를 확인한 후, 적절한 디바이스 드라이버의 IRP 큐에 IRP를 큐잉한다.
- 개별 디바이스 드라이버는 자신만의 IRP 큐를 가지고 있으며, 이 큐 에는 현재 컴퓨터에서 수행 중인 모든 프로세스로부터의 I/O 요청이 큐잉된다. IRP 큐에 IRP가 큐잉되면 디바이스 드라이버는 IRP 정보를 회로기판의 실제 하드웨어로 전달하고, 하드웨어 디바이스는 요청된 I/O 작업을 수행한다.
- 하드웨어 디바이스가 I/O 작업을 수행하는 동안 I/O 작업을 요청하였던 사용자 스레드는 아무런 할 일이 없다. 따라서 운영체제는 사용자 스레드가 CPU 시간을 낭비하지 않도록 슬립상태로 변경한다.
- 이를 통해 스레드가 CPU 시간을 낭비하지는 않겠지만, 스레드가 접근수 없는 메모리 공간(유저모드스택, 커널모드스택, TEB와 그 외의 여러관련 데이터들을 저장하고있는 메모리 공간등)을 차지
- GUI 응용프로그램의 경우에 이처럼 UI 스레드가 블로킹되면 사용자의 요청에 반응하지 않는 상태가 돼 버림 -> 안좋음
7, 8, 9 윈도우 운영체제는 사용자 스레드를 깨워서 다시 CPU가 스케줄링 할 수 있도록 해줄것이다. 이제 커널모드 -> 유저모드 -> 관리코드로 까지 전환이 일어난다.
이 과정을 거치면, FileStream의 Read 메서드는 실제로 파일로부터 읽어온 바이트 수를 Int32값으로 반환하고, 사용자는 디스크로부터 몇 바이트나 읽어왔는지를 확인 한 후, 앞서 전달한 Byte[]로부터 값을 가져온다.
Ex ) 동기로 I/O작업을 수행하는 경우
- 웹 응용프로그램 ( 사용자들의 요청이 있을때마다 데이터베이스에서 값을 가져오는 경우 )
- 사용자의 요청이 들어오면 스레드 풀 내의 스레드가 웹 응용 프로그램의 코드를 수행함.
- 만일 데이터베이스로의 요청이 동기적으로 수행되어야한다면, 이 스레드는 데이터베이스가 응답할 때까지 영원히 블로킹된 상태로 있게 됨.
- 만약 다른 사용자의 요청이 또 들어오면, 스레드 풀은 스레드를 생성하고 데이터베이스가 응답할때까지 블로킹함.
- 이렇게 생성된 스레드들은 모두 데이터베이스가 응답할 때까지 블로킹 되고, 웹서버는 거의 사용하지도 않는 상당량의 시스템 리소스를 할당하게 됨.
- 데이터베이스로부터 응답이 온 후, 블로킹 되어있던 스레드가 모두 깨어나면 -> CPU 코어수가 많지 않은 컴퓨터인 경우 너무 많은 스레드를 수행해야 함.
=> 이는 확장성 있는 응용프로그램을 구현하는 방법이 아니다.
-
-> 여러스레드를 동시에 수행하기 위해 더 자주 컨텍스트 전환을 해야 됨 (성능에 좋지 않음)
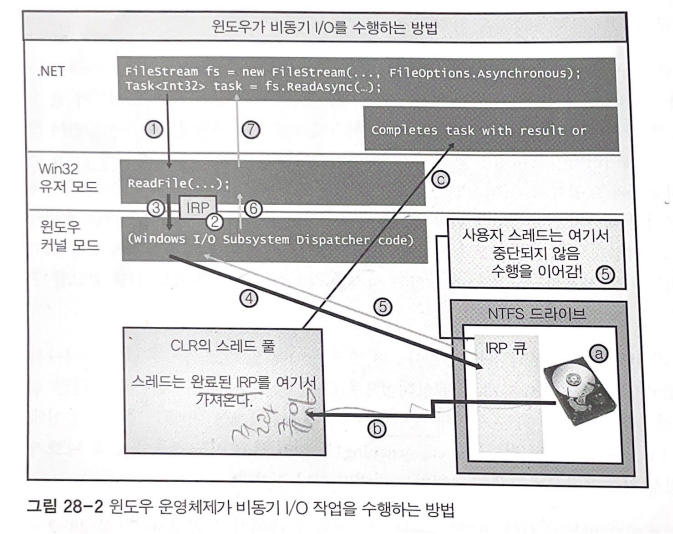
- ReadAsync는 Win32의 ReadFile 함수를 호출한다.
- ReadFile은 IRP를 할당하고 동기 시나리오에서와 동일한 방식으로 IRP를 초기화한다.
- 이제 이 값을 윈도우 커널로 전달한다.
- 윈도우 운영체제는 전달받은 IRP를 하드디스크의 IRP큐에 큐잉한다.
5,6,7. 사용자 스레드를 블로킹하지 않고 반환. 사용자 스레드는 ReadAsync를 호출한 부분까지 반환
- IRP는 아직 처리되지 않았으므로 ReadAsync 이후에 앞서 전달하였던 Byte[]를 통해서 내용에 접근할 수는 없다.
- ReadAsync를 호출하면 반환되는 Task<int32> ContinueWith를 이용하면 태스크가 완료시 호출되는 콜백 메서드를 등록가능하기 때문에, 이 콜백 메서드 내부에서 데이터를 처리.
- 하드웨어 디바이스가 IRP 요청을 완료하면
- 완료된 IRP를 CLR의 스레드 풀에 큐잉한다.
- 스레드 풀 내의 스레드는 완료된 IRP 스레드를 가져와서 예외를 설정하거나, 작업의 결과 값을 설정한다.
=> 여기까지 완료되면 Task 객체는 자신이 나타내는 작업이 완료되었음을 알게 되고, 이후 사용자 코드를 수행하여 안전하게 Byte[] 내부에 있는 데이터에 접근할수 있다
ex) 비동기로 I/O작업을 수행하는 경우
- 웹 애플리케이션 시나리오
- 클라이언트의 요청이 들어오면 서버는 비동기 데이터베이스 요청을 만들어 낸다.
- 스레드는 블로킹되지 않기때문에 스레드 풀로 즉시반납되고 추가적인 사용자 요청을 처리할 수 있게 된다.
-> 하나의 스레드만으로도 모든 클라이언트의 요청을 처리
- 데이터베이스가 응답을하면, 그 결과 또한 스레드 풀로 큐잉되므로, 스레드 풀 내의 스레드가 그 결과를 처리하고 클라이언트로 결과를 주게 됨.
-> 모든 데이터베이스의 응답까지도 하나의 스레드만으로 처리
=> 이런식으로 최소한의 시스템리소스만을 필요로하며, 특별히 컨텍스트 전환도 필요하지 않기 때문에 최고의 속도로 수행
만일 스레드 풀에 작업이 삽입되는 속도보다 스레드가 작업을 처리하는 속도가 느리다면?
- 스레드 풀은 추가적으로 스레드를 생성할수도 있다. (컴퓨터에 설치된 CPU 개수만큼)
- 따라서 네개의 프로세서가 설치된 컴퓨터라면 네 개의 클라이언트 요청 혹은 데이터베이스 응답에 대한 처리가 컨텍스트 전환 없이도 동시에 수행될수 있다.
만일 스레드가 자발적으로 블로킹을 수행하면 어떻게 될까? (동기 I/O작업 수행, Thread.Sleep을 호출)
- 윈도우 운영체제는 스레드 풀에게 수행중이던 스레드 중 하나가 블로킹 되었음을 알림
- 이제 스레드 풀은 CPU가 충분히 사용될 수 없음을 인지하고, 블로킹 된 스레드를 대체할 새로운 스레드를 생성
- 이상적인 방법은 아님 (새로운스레드 생성에는 소요시간과 메모리 사용에 있어서 상당히 비싸기 때문)
- 블로킹 되었던 스레드가 깨어나서 CPU가 수행해야할 스레드의 개수 > CPU의 개수 가 되면 컨텍스트전환발생 -> 성능저하
하지만 스레드 풀은 이보다 훨씬 세련되게 동작한다.
- 스레드 풀에 있던 스레드가 특정 작업을 완료한 후 반납될 때, CPU사용수준을 확인하여 만일 CPU가 사용중이라면 새로운 일을 반납된 스레드에게 할당하지 않는다.
-> 컨텍스트 전환 감소 -> 성능개선
- 스레드풀에 필요 이상으로 스레드가 많다고 판단되는 시점이 되면, 추가적인 스레드들을 종료하여 사용하던 리소스를 반납
위와 같은 내용들을 구현하기 위해, 내부적으로 CLR의 스레드 풀은 I/O 컴플리션 포트라고 부르는 윈도우 리소스를 사용하고 있다.
- CLR은 하드웨어 디바이스에 대하여 열기 작업을 수행할 때 I/O컴플리션 포트를 생성 후, 디바이스와 I/O 컴플리션 포트를 결합하여
추후 이 디바이스 드라이버가 작업을 완료한 후, 완료된 IRP를 어디로 큐잉해야 하는지를 판단할 수 있도록 해준다.
I/O작업을 비동기적으로 수행함으로 취할수 있는 장점
- 리소스의 사용량과 컨텍스트 전환의 횟수를 최소화
- 가비지 수집이 빨리 완료할수 있게 함
- 가비지 수집을 수행하려면 CLR은 반드시 프로세스 내의 모든 스레드를 중단해야한다. 따라서 스레드개수가 적을수록 빠르게 가비지 수집이 된다.
- 또한 가비지 수집이 시작되면 모든 스레드의 스택을 뒤져서 루트를 찾아내는데, 이 또한 스레드 개수가 적으면 살펴볼 스택의 개수가 적어져서 빠르게 가비지 수집이 된다.
- 가비지 수집이 수행되더라도 루트 검색이 매우 빠르게 끝나게 된다.
- 블로킹되지 않는 스레드들은 상대적으로 스레드 풀에 머물러 있는 시간이 많을수밖에 없고, 가비지 수집이 수행되더라도 사용한 스택의 크기가 작고, 스택의 상단에 머물기에 빠르다.
- 디버깅 성능개선 (스레드 개수가 최소화)
- 브레이크포인트에 도달하게 되면 윈도우 운영체제가 모든 스레드를 정지후, 각각의 스레드를 조사 -> 이후, 응용프로그램을 진행시키면 모든 스레드를 재개하는데,
-> 이때 너무 많은 스레드가 있으면 시간이 오래 걸린다. 스레드 개수가 최소화 되기 때문에 성능도 개선
- I/O작업을 동기적으로 수행하는 경우보다 빠르게 작업 완료
- GUI 응용프로그램의 경우 응용프로그램의 사용자 인터페이스를 중단하지 않고, 항상 사용자에게 응답할수 있는 상태로 유지
- 실제로 마이크로소프트의 실버라이트나 윈도우 스토어 앱을 개발할 때에는 I/O 작업을 수행하는 메서드가 비동기 전용으로만 제공되고 동일한 기능을 수행하는 동기함수는 제공되지 않기 때문에 모든 I/O작업을 비동기로 수행할수밖에 없다.
- 비동기로만 제공하는 이유 : GUI 스레드가 동기 I/O 수행함에 따라 블로킹 되고 이로 인해 사용자의 요청에 응답하지 않는경우를 미연에 방지
- 개발자들이 최종사용자에게 좀 더 나은 사용자 경험을 제공할수 있도록 하기 위함